Predicting Heat Capacity with Molecular Descriptors
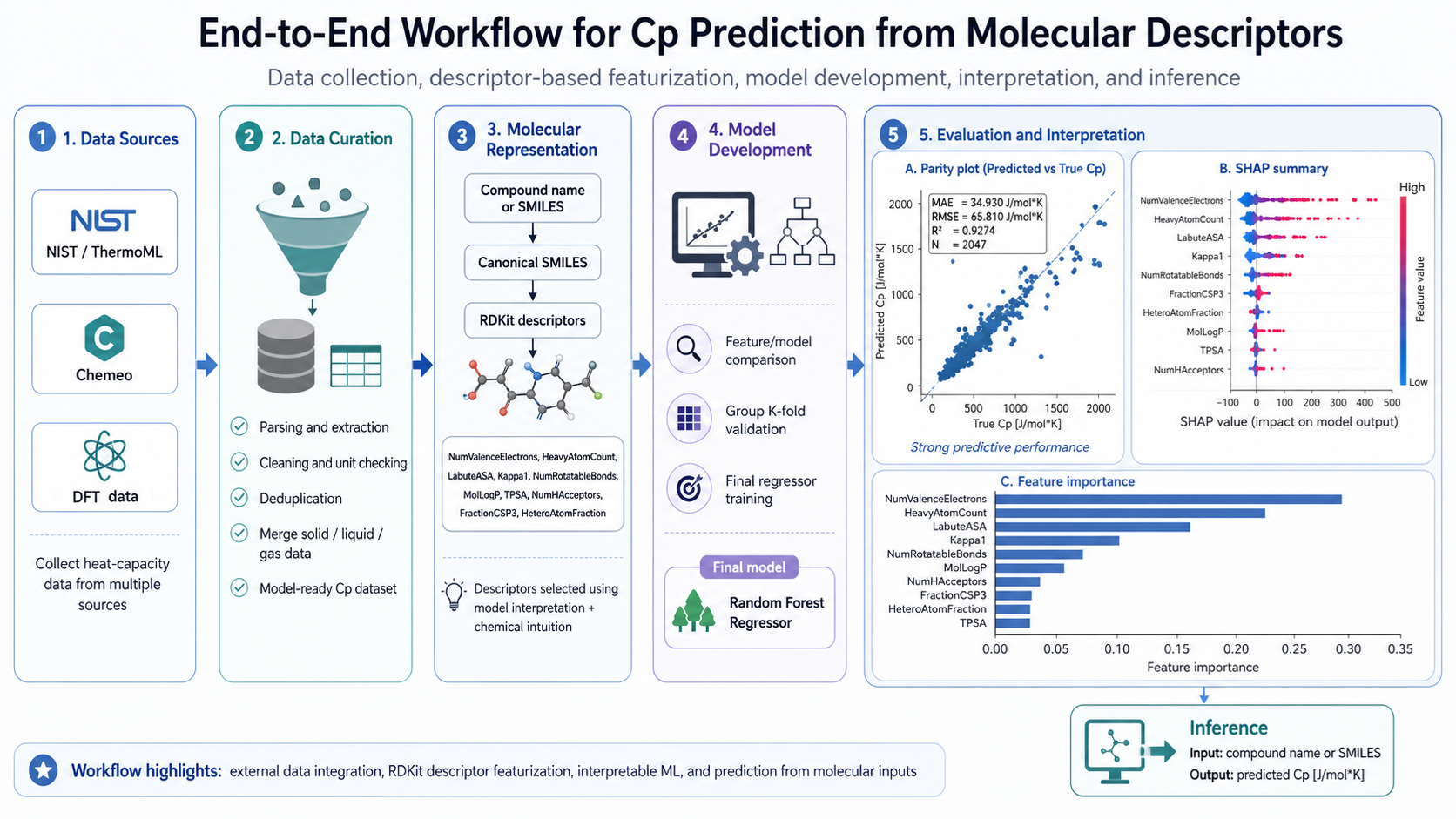
2026This project builds a reproducible machine-learning workflow for predicting the constant-pressure heat capacity, Cp, of chemical compounds. A key focus was expanding and polishing the dataset from external sources and representing molecules using descriptors calculated directly from SMILES.
What it does
- Extracts and organizes heat-capacity data from NIST/ThermoML and other external sources.
- Merges, cleans, and deduplicates datasets into a model-ready Cp dataset.
- Predicts Cp using molecular descriptors computed from SMILES in a reproducible ML workflow.
Contributions
Designed the end-to-end workflow from data extraction to final prediction. Built the NIST/ThermoML parsing pipeline, organized dataset polishing and integration steps, evaluated descriptor/model combinations, and developed the final Cp prediction workflow.
Technical highlights
- Structured pipeline for raw, clean, and representative Cp datasets.
- Descriptor-based featurization using RDKit from SMILES.
- Final regression workflow with model interpretation and prediction from compound name or SMILES.
Figure
How to run
git clone https://github.com/Gibeom-KIM-02/Predicting_Heat_Capacity
cd Predicting_Heat_CapacitySee the repository README for environment setup, dataset-building steps, model training, and inference workflow.